Inhaltsverzeichnis
LZW-Kompression
Die LZW-Kompression ist ein Wörterbuchverfahren nach Lempel-Ziv-Welch.
Wörterbuchverfahren hinterlegen wiederkehrende Zeichenfolgen in einem Wörterbuch. Kommen diese Zeichenfolgen dann im zu komprimierenden Text erneut vor, reicht ein Verweis auf diesen Eintrag. Das LZW-Verfahren arbeitet dabei mit einem dynamischen Wörterbuch, welches direkt während der Kompression selbst erzeugt wird und damit keinen zusätzlichen Speicherplatz benötigt.
Um Platz für das Wörterbuch neben den normalen (ASCII-)Zeichen zu schaffen, reichen 8 Bit nicht aus. Für gewöhnlich werden 12 Bit für jedes Zeichen bzw. jeden Wörterbucheintrag verwendet. Das Wörterbuch kann also maximal 212 = 4096 Zeichen und Zeichenkombinationen beinhalten, wovon die ersten 256 Einträge bei Texten fest mit den ASCII-Zeichen vorbelegt sind.
Die Codierung verläuft nach folgendem Algorithmus:
- Lies eine möglichst lange Zeichenkette ein, die bereits im Wörterbuch steht. Zu Beginn ist das jeweils nur ein einzelnes Zeichen!
- Schreibe den Code des gefundenen Eintrags in die Ausgabe.
- Lege aus der eben gefundenen Zeichenkette und dem nachfolgenden Zeichen einen neuen Wörterbucheintrag mit der nächst möglichen Codierung an.
- Wenn nötig wird das letzte Byte der Ausgabe mit 0 aufgefüllt
Beispiel
Codierung
 Die Zeichenkette
Die Zeichenkette BABAABBAA soll mit LZW codiert werden. Das Wörterbuch ist zu Beginn des Vorgangs im Bereich von 00016 bis 0FF16 mit den ASCII-Zeichen befüllt1). Zum besseren Verständnis des weiteren Ablaufs sollte man im Hinterkopf haben, dass der ASCII Code des großen A 6510=4116 ist, der des großen B 6610=4216.
Die Codes ab 10016 stehen dann für Wörterbucheinträge zur Verfügung - der erste Wörterbucheintrag bekommt den Code 10016, der zweite 10116 u.s.w. So kann jedes Zeichen/Zeichenkombination des Wörterbuchs mit 12Bit codiert werden.
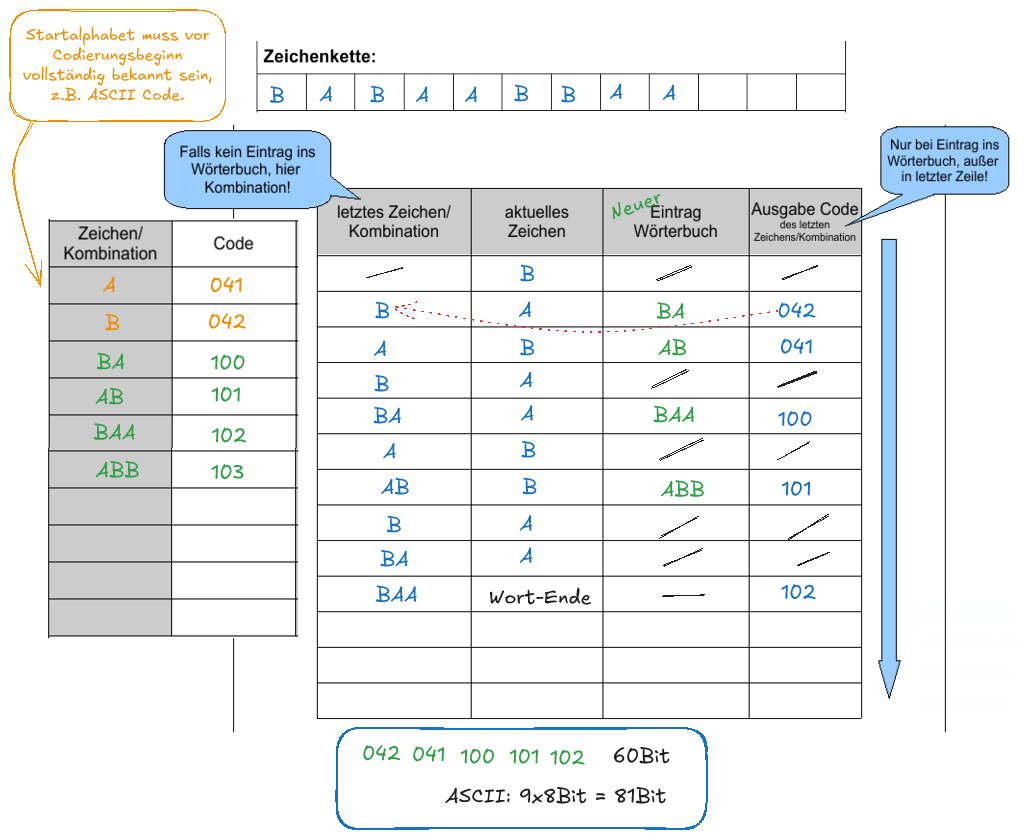
Die Zeichenfolge wird also folgendermaßen codiert: 04204110010110216. Das sind 7,5 Bytes 2). Die Kompression ist also bei solch kurzen Zeichenketten noch nicht drastisch - wenn man sich jedoch vorstellt, dass das Wörterbuch stets längere Zeichenketten mit einem einzigen 12Bit Code zugreifbar macht, kann die Kompression unter Umständen bei längeren Texten deutlich stärker ins Gewicht fallen.
Decodierung
Bei der Decodierung werden 12-Bit-Blöcke eingelesen.
Das Wörterbuch wird während des Vorgangs mit Einträgen befüllt die aus allen Zeichen des Vorangehenden Eintrags und dem ersten Zeichen3) des aktuellen Eintrags bestehen.
Wir nehmen den codierten String von oben: 042 041 100 101 10216.
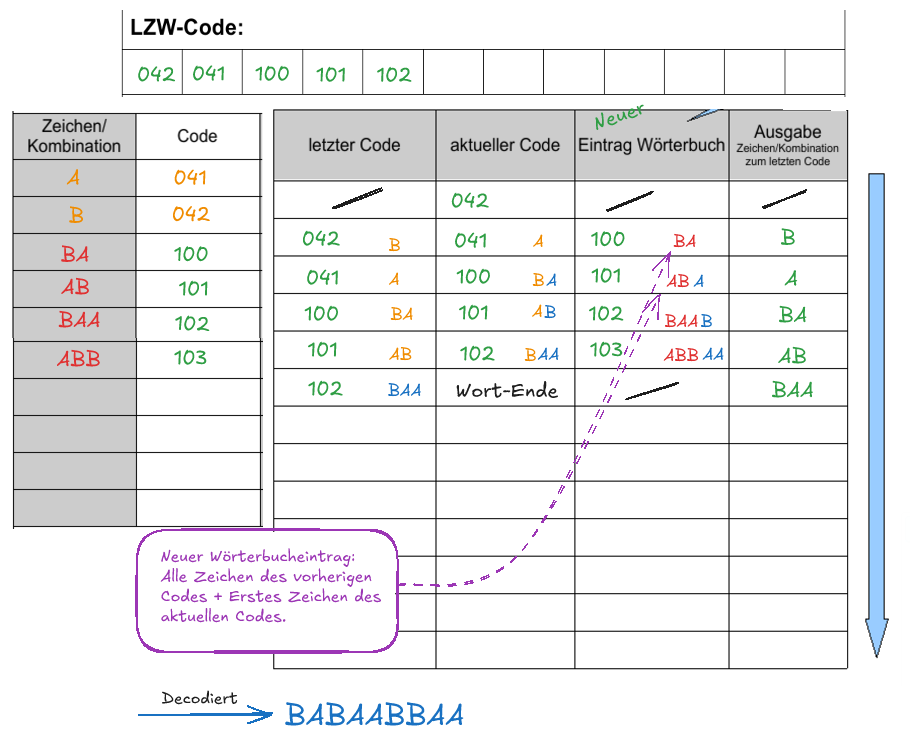 Decodiert lautet der Text also
Decodiert lautet der Text also BABAABBAA.
Anmerkung: Das Wörterbuch musste zur Decodierung hier nicht gesondert übertragen werden - es "ensteht" während des Vorgangs.
Für die Aufgaben kannst du die folgenden Arbeitsblätter verwenden:

(A1)
Codiere den Text ABABCABCDABCD und vergleiche die codierte und die uncodierte Länge miteinander.
(A2)
(A3)
(A4)
Der folgende LZW-Code: 0 1 2 4 6 5 7 7 3 codiert eine Pixelgrafik, die 4 Pixel breit ist. Die einzelnen auftretenden Pixel haben den folgenden "Grundcode":
![]()
(A5)
Erläutere in einem kurzen Text das Grundprinzip der Komprimierung beim LZW-Verfahren.
(A6)
Begründe, dass das LZW-Verfahren nicht jede Eingabe komprimieren kann.
Material
| Filename | Filesize | Last modified |
|---|---|---|
| 01_lzw-vorlage-codierung.odt | 479.1 KiB | 03.10.2022 16:53 |
| 01_lzw-vorlage-codierung.pdf | 74.6 KiB | 03.10.2022 16:53 |
| 01_lzw-vorlage-decodierung.odt | 478.4 KiB | 03.10.2022 16:53 |
| 01_lzw-vorlage-decodierung.pdf | 73.4 KiB | 03.10.2022 16:53 |
| 06-kompression-lzw.odp | 43.0 KiB | 29.09.2022 07:20 |
| 06-kompression-lzw.pdf | 157.1 KiB | 29.09.2022 07:20 |
| ab.png | 9.9 KiB | 03.10.2022 15:58 |
| lzw-codierung-beispiel.png | 130.2 KiB | 14.01.2025 09:15 |
| lzw-decodierung-beispiel.png | 94.9 KiB | 14.01.2025 09:06 |
| lzw_a2_cod_dec.odp | 78.4 KiB | 05.12.2023 14:01 |
| lzw_a2_cod_dec.pdf | 81.5 KiB | 05.12.2023 14:01 |
| pixel.png | 2.0 KiB | 03.10.2022 17:01 |